Johan Bollen & Francis Heylighen
Center "Leo Apostel", Free University of Brussels,
Pleinlaan 2, B-1050 Brussels, Belgium
email: jbollen@vnet3.vub.ac.be, fheyligh@vnet3.vub.ac.be
Abstract[ ]
This paper describes our attempts to devise a number of algorithms that can make distributed hypertext networks such as the World Wide Web self-organise according to their users' knowledge. A number of experiments were conducted in which experimental networks of English nouns were being browsed via the Internet by several thousands of participants. These experimental networks evolved into a stable state which represented the participants shared knowledge structure and associations.
It is this network-like character that has inspired a number of authors to suggest "neural" metaphors for the WWW functioning and structure. Mayer-Kress (1994)] discussed the possibility of a global brain, capable of information and knowledge processing, spontaneously emerging from the enormous amount of nodes and their continuously evolving connections. Others suggested to study the WWW as an adaptive neural network, where the list of `Bookmarks' (stored favourite connections) controls human activity patterns and thereby acts as a possible adaptation mechanism for the network.
In spite of these similarities, the WWW lacks some important functional attributes typical for biological and artificial neural networks. First, neural networks are normally not intended to merely store information, but to control and guide goal-directed behaviour. The WWW, however, does not perform any tasks except information storage. Second, most neural networks are equipped with mechanisms to adapt the knowledge and models they contain. This phenomenon lies at the heart of an error-correcting feedback loop, characterizing biological as well as artificial neural networks [Mc. Clelland & Rumelhart, 1986]: `knowledge -> behaviour -> effect -> perception -> knowledge adjustment'. The WWW does not have any such error-correcting mechanisms. It evolves, but does not adapt.
One might argue that it is not the WWW's goal to simulate brains or neural networks, but to provide a reliable and user-friendly access to stored knowledge. But it is questionable whether the present WWW--and the hypermedia paradigm in general [Nielsen, 1990]--succeeds in this [Jonassen, 1989; 1993]. The WWW's content is presently expanding at an enormous pace, but the quality of its structure does not seem to improve. This should not surprise us, as the only mechanism for network restructuring at present are the contributions of individual web-designers, each adding their own, often poorly designed, sub-networks to the WWW. The WWW, being not more than the sum of its parts, can achieve no better quality of structure than that of these sub-networks. This causes the WWW to be, in general, very poorly organized, which in its turn seriously hampers efficient and user-friendly retrieval of information [Hamond, 1993]. With an ever-expanding amount of information being added to the WWW, this problem can only be expected to worsen within the present set-up.
We believe the only solution to these practical and fundamental problems is to move beyond metaphors and implement the necessary conditions to make the WWW really function in a more "brain-like" manner [Heylighen & Bollen, 1996]. As a first step in that direction, we tried to design a mechanism for the self-organization of a hypertext network. Our goal was to develop algorithms that would allow the WWW to autonomously change its structure and organise the knowledge it contains, by "learning" the ideas and knowledge of its human users as manifested in their browsing behaviour, thus producing a more ergonomic and user-friendly network.
When entering the network, users were presented with a node representing a word (e.g. "Cat"). Below the title word, ten other words (e.g. "car", "dog", "mouse", "house", etc.) were listed, each linking to the respective nodes representing that word. The users were asked to select from that list the word that has the strongest association with the title word. Once they had selected a good association for the word "Cat", say "dog", they would be presented with the "Dog" node, again with a list of possible associations (e.g. "garden", "barking", "water", etc.) to select from. Thus, they could wander through the network, each time selecting new associated nodes, until they lost interest and quit the experiment.
Each time a subject contacted our server and requested to take part in the experiment, he/she was assigned a random starting position in the network of nouns. The stack then returned an HTML page with the name of the present node on top, followed by an ordered list of the 10 highest ranking associated words, each hyperlinked to the node representing that word. If the subjects did not find a sufficiently good association in the list, they could select a "More words..." link at the bottom of the page, which would call up a new list with the 10 next ranking nouns. By repeatedly selecting this link, they could in principle go through all 149 possibilities in the order of decreasing connection weight (although this never seemed to happen). Figure 1 illustrates the properties of the interface and the underlying system of rewards for a hypothetical path through the nodes dog, cat and mouse.
Figure 1: Schematic representation of the experiment's interface and underlying learning rules. Circles and arrows denote established connections.
Subjects could travel the entire network at will by repeatedly selecting the "best" association from the list of proposed connections. If a user selected a link, the stack would immediately adjust the connection strengths according to the learning algorithms and sort the connections according to their new strengths, so that the next time a subject would visit the same node, the order of the links might have changed. Thus, links which previously were not strong enough to appear among the 10 strongest ones, might make the transition to this list of links which is directly visible to the user, and thus become "actual". Similarly, links that would lose strength relative to the other ones, might disappear from the "actual" list, and thus become more difficult to select.
Frequency applies selection to the network by selectively encouraging the use of already established connections, thereby indirectly inhibiting the use of unpopular links. (rarely used links would diminish in rank, move down on the ordered list of links, and therefore become more difficult to select by the user).
Transitivity opens up an unlimited realm of new links. Indeed, one or several increases in strength of A -> C may be sufficient to make a previously "potential" link actual (move it to the first 10). The user can now directly select A -> C, and from there perhaps C -> D. This increases the strength of the potential link A -> D, which may in turn become actual, providing a starting point for an eventual further link A -> E, and so on. Eventually, an indefinitely extended path may thus be replaced by a single link A -> Z. Under the assumption that browsing behaviour is goal-directed, the transitivity rule bridges intermediate nodes and reduces the number of links that have to be followed to reach the destination.
Sometimes the new connections introduced by transitivity are spurious (e.g. Cat->Mouse->Cheese => Cat->Cheese?), but this will be corrected by the Frequency learning rule rewarding only the worthwhile links.
Symmetry too introduces new connections to the network by reinforcing connections that have not explicitly been chosen, but it is more limited in that respect than transitivity since only a single symmetric link can be generated for every existing link. Frequency will afterwards determine whether these links will further develop or not. The symmetry rule was only used in the second experiment.
It must be noted that the symmetry and transitivity rules have a synergetic effect that cannot be produced by a single rule. For example, consider two links A1 -> B, A2 -> B. The fact that A1 and A2 point to the same node seems to indicate that A1 and A2 have something in common, i.e. are related in some way. However, none of the rules will directly generate a link between A1 and A2. Yet, the repeated selection of the link A2 -> B may actualize the link B -> A2 by symmetry. The repeated selection of the already existing link A1 -> B followed by this new link B -> A2 can then actualize the link A1 -> A2 through transitivity. Similar scenarios can be conceived for different orientations or different combinations of the links.
Given the choice of Fb as unity, the values of Tb and Sb are largely arbitrary and are not considered critical for the functioning of our algorithms. We have chosen them such that they seem to provide a good balance between the amount of variation and selection.
MIND
0 600 1200 2400 4200
table thought thought thought thought
order idea idea idea idea
figur research research knowledg knowled
e e ge
party problem change developm view
ent
quest need need change educati
ion on
schoo light knowledg theory theory
l e
act developm problem research develop
ent ment
histo change developm need researc
ry ent h
fact view example educatio change
n
wife law life view problem
Table
1: self-organization of the list of 10 strongest links from the word
"Mind", in different stages: initial random linking pattern, after 600, 1200,
2400 and 4200 steps. (a step corresponds to a user selecting one link on one of
the 150 nodes in the network)
A typical example of how connections are gradually introduced and rewarded until their strength reaches an equilibrium value, may illustrate how fast and efficient the self-organising process was: Table 1 provides an overview of the connections that were formed as the node `Mind' became connected to related nodes. The position of these associated words shifted upwards in the list until they reached a position that best seemed to reflect their relative strength.
At the end of each experiment, after some 6000 selections, the most frequented nodes had gathered a list of 10 strongest links that quite well reflected their direct semantic environment, with words that were near synonyms of the node name at the top of the list (see Table 1). However, this positive result was much less strong in the less frequented nodes, because of what we termed the "attractor effect". Nodes that had many incoming links, by accident, or because they were associated with many other words in the list, would tend to attract more users. This would result in increasing strength of their incoming paths, and their replacement by even stronger direct links. Especially in the first experiment, almost all paths would end up in a cluster of semantically related, strongly cross-linked nodes, forming an approximate attractor for the network. Although the random assignment of starting nodes meant that all nodes would be consulted on first entry with the same average frequency, the subsequent moves would very quickly end up in the attractor cluster. As a result, nodes outside the attractor would get little chance to learn and thus remain poorly connected.
In our second experiment, the introduction of the symmetry rule attenuated this effect, since strong links leading into an attractor would necessarily produce weaker, inverse links leading out of the attractor. This gave nodes outside the attractor the chance to develop some links of their own, generating new local attracting clusters, weakly connected to other clusters. The overall learning seemed more efficient in the sense that less time was needed to develop good associations, and the result was more balanced, in the sense that the differences in frequentation between nodes were less strong.
"Time": age, time, century, day, evening, moment, period, week, year
"Space": place, area, point, stage
"Movement":action, change, movement, road, car
"Control": authority, control, power, influence
"Cognition": knowledge, fact, idea, thought, interest, book, course, development, doubt, education, example, experience, language, mind, name, word, problem, question, reason, research, result, school, side, situation, story, theory, training, use, voice
"Intimacy": love, family, house, peace, father, friend, girl, hand, body, face, head, figure, heart, church, kind, mother, woman, music, bed, wife
"Vitality": boy, man, life, health
"Society": society, state, town, commonwealth
"Office": building, office, work, room
Although the learning algorithms only work on links and not on groups of nodes, it is remarkable how well the resulting clusters fit in with intuitive categories. With rare exceptions (e.g. "side" in the "Cognition" cluster), all of these words seem to be located in the right class. This again seems to confirm that the set-up achieves its aim of absorbing the common semantics of a heterogeneous group of users. The `cognition' cluster makes up 33% of all words over all clusters, indicating its central position and importance in the network. It should be noted that this prominence may be due to the specific selection of texts in the LOB corpus, which may have been biased towards more "intellectual" activities.
Apart from the less deleterious "attractor" effect mentioned earlier, such a distortion did not seem to occur. This is probably due to the continuous generation of novel links by transitivity and symmetry, which can quickly displace unjustly reinforced existing links. The relatively weak sensitivity for initial conditions can be seen by comparing the results of the two experiments. The experiments were conducted independently within an interval of 3 months, with a different random initialization of connection weights, a different group of subjects, and the addition of the symmetry rule in the second experiment. Yet both delivered quite similar final network structures. Cluster analysis showed an overlap of 76% over all clusters in the two experiments. This result, however, cannot be considered conclusive evidence of developmental stability since quantitative comparison between associative networks remains a difficult task, and our two experiments can certainly not be considered adequate samples.
The beneficial effect of this feedback loop was that it considerably speeded up network development. Feedback can strengthen new connections introduced by Symmetry and Transitivity in a fast loop of continuing rewards, administered by the Frequency learning rule. Any worthwhile link could as such rapidly achieve a high position, and pull transitively or symmetrically related links up in its wake.
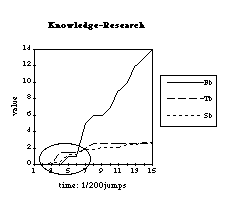
Figure 2 Cumulative weight over all network states for the connection Knowledge->Research split up in Symmetry (Sb), Transitivity (Tb) and Frequency (Fb) bonuses.
This indicates that at least 6 out of 20 high scoring connections were introduced to the network's structure by transitivity and symmetry rather than the human browser's active selection. Due to the rather large interval of 200 jumps between subsequent measurements of network state, apparently `simultaneous' onsets of rewards from all three learning rules could not be resolved into separately measured events, and so we expect this number to be even higher in reality. An example of this pattern is shown in Figure 2. These data also support the acceleration through feed-back as hypothesized in the previous section.
First, the present experiment is run by a single application on a single server. This facilitates the exchange of information between the different nodes. An implementation on the web would require a change to the HTTP protocol that controls the communication between servers and browser applications. The protocol already includes a "Referer" line, which tells the server from which previous node B the present node C was linked to. To implement the symmetry rule the server may use this information in order to reinforce a potential link from C to B. The transitivity rule requires a more substantial change, since it requires the introduction of the additional address of a "Previous Referer", i.e. the node A which referred to B, which in turn referred to C. The server getting a request for C should then be able to signal this to the server that originally provided A, so that it could strengthen a potential link from A to C.
The creation of new links is not obvious in the present HTML protocol for hypertext, since links are embedded in the text of a document, and thus are difficult to change. This obstacle is overcome in the Hyper-G system, which proposes an enhanced version of the World-Wide Web, though it appears similar to casual users. In Hyper-G, links are separate from the document and under the control of the server. This makes it easy to add a list of "learned" links, e.g. at the bottom of a document, which would provide the user with further possibilities for navigation, in addition to the (unchanging) links provided by the author of the document. Initially, this list would be empty, but as soon as selections are made, transitivity and symmetry will start adding potentially related documents. The server should only show the highest ranking links to the user, and keep the others in memory until they gather sufficient strength (or until a user requests to see "more links").
Another difference with the experimental set-up is that Web documents typically contain texts or graphics and not just a list of linked nodes. Thus, users, when judging whether a document is interesting, will need more than the name or title provided by the link. A link that seems promising may well lead to a document with an irrelevant or useless content. Therefore, the learning mechanism should need some kind of "quality control". The most obvious, but least user-friendly, way to implement this, would be to let the user evaluate the usefulness of the document before transmitting the bonus. A less obtrusive, but perhaps less reliable, method would be to only transmit a bonus after the user has stayed for a sufficiently long time with the same document, or selected a further link in this document. Link selections immediately followed by backtracking to a previous document should not be strengthened. Perhaps the user himself or herself may decide to "reward" particularly good nodes, and "punish" particularly bad ones, whereas a background mechanism would make an estimate of usefulness in all other cases.
Such enhancements require a more sophisticated exchange of messages between browser and server than provided by the present HTTP, but may lead to a much higher quality Web, without making additional demands on users and authors. The criticism that selecting links on the basis of frequent use will merely strengthen "conventional wisdom" or the "lowest common denominator", stifling creative, original or unpopular associations, is misdirected. First, the links made initially by the author of the document are not touched by the mechanism, and thus there is no restriction on introducing non-conformist associations. Second, the popularity of a link only matters relative to the other links "learned" by the same document. Specialized or controversial documents will normally only be consulted by a limited public interested in the specific subject of these documents. These users are likely to continue their search for more information about this little known domain, thus creating more specialized links, and not to suddenly jump to mainstream, popular subjects. As a group, they are likely to know more about the subject than the individual author, and are therefore likely to select relevant links unknown to that author.
The practical advantages of these such algorithms in terms of efficient hyper-structure are obvious. Hypermedia networks for storage and retrieval of information are becoming increasingly important tools, but the paradigm's complete dependence on human network design is a serious limitation to the further development of this medium. This structural problem can only worsen with an increasing amount of information being added.
We believe that these algorithms can be further extended to solve many fundamental and practical problems of the present World-Wide Web. With a number of minor technical adjustments to the protocols and servers, these learning rules could transform the WWW as we know it into a truly adapting and active associative network. It would be able to absorb the implicit knowledge of its users and discover new relations between pieces of information. Such a world-wide associative network can be seen as the first step towards a "global brain". [Heylighen et al., 1996] and [Mayer-Kress et al. 1994] discuss this `super-brain's enormous potential for humanity, but even the simple addition of associative learning might be sufficient to spectacularly increase the power of the Web.
Hinton, Geoffrey en James Anderson ed. Parallel Models of Associative Memory. Hillsdale, N.J., 1981.
Hamond, N.: Learning with Hypertext: Problems, Principles and Prospects, In: Hypertext: a Psychological Perspective, p. 51, ed. C. McKnight, A. Dillon and J. Richardson, Ellis Horwood, 1993
Heylighen, F.: Selection criteria for the Evolution of Knowledge, Proc. 13th Int. Congress on Cybernetics, Namur, 1995.
Heylighen F. & Bollen J. : The World Wide Web as a Super-Brain: from metaphor to model, Cybernetics and Systems `96, World Science- Singapore (this volume), 1996.
Hull, C. L. : "The acquisition of receptor - Effector Connection. Primary reinforcement" in Robert C. & Richard Teevan (ed.), 1961, "Reinforcement", part 1 pp9 - 15, D. Van Nostrand Company, Inc.
Johansson S. & Hofland, K.: Frequency analysis of English vocabulary and grammar: based on the LOB corpus, Oxford : Clarendon Press, 1989. - 2 v.
Jonassen D. H.: Effects of Semantically Structured Hypertext Knowledge Bases on Users' Knowledge Structures. in: Hypertext: A Psychological Perspective, p. 153, ed. C. McKnight, A. Dillon and J. Richardson, Ellis Horwood, 1993
Jonassen, D. H. : Semantic Network Elicitation: Tools for Structuring Hypertext in "HYPERTEXT II: State of the Art", p. 142-152, 1989
Mayer-Kress, G. & Barczys, C.: The Global Brain as an Emergent Structure from the Worldwide Computing Network, and its Implications for Modelling, The Information Society, Vol 11 No 1, 1994.
Mc. Clelland, J. & Rumelhart, D. E.: Parallel Distributed Processing.Volume 1: Foundations, Bradford Books, MIT Press, 1986.
Nielsen, J.: Hypertext and hypermedia. Academic Press, 1990.
Thorndike, E. L.: The law of Effect, excerpt from Dalbir B. & Stewart, J., "Motivation", Nature of Reinforcers pp 184 - 187, Penguin Books, 1966.